
Most apps have data stored in a database.
Databases write their data to disk so it can be retrieved.
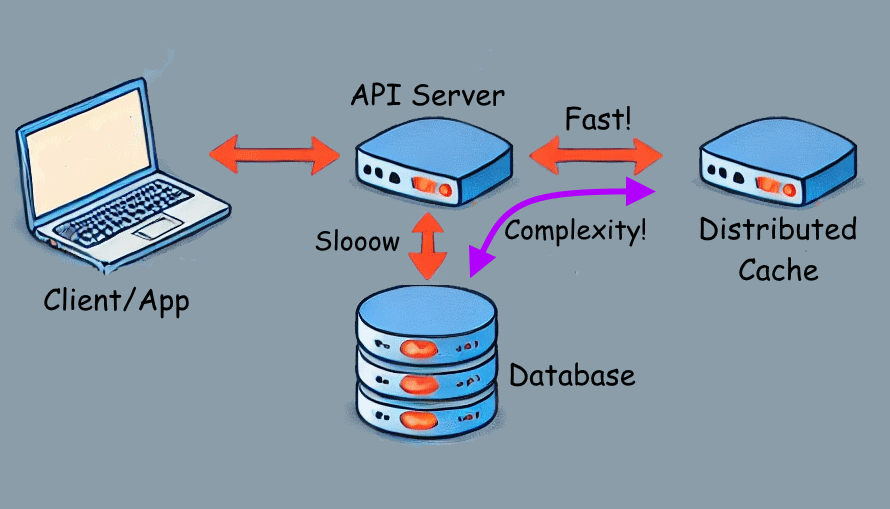
Writing and reading data from disk is comparatively slow and can cause bottlenecks.
One optimization is to store frequently accessed data in memory to avoid reading from disk. This can provide huge performance gains, especially with heavy traffic!
There are two ways to cache:
🧠 In memory: The server that processes a request stores the data in its memory for later retrieval.
🌐 Distributed: The data is stored in memory on a different server and can be shared by multiple API servers.
The main challenge of caching is maintaining cache consistency. Code accessing the cache needs to be coordinated with mechanisms like locking to prevent conflicts and ensure data integrity.
Another challenge is cache invalidation—knowing when to update or remove data from the cache. Caches often use TTL (Time-to-Live) settings to automatically invalidate entries after a certain period.
Adding caching introduces significant complexity, as caches need to be kept in sync, and bugs can be hard to diagnose.
What I have learned:
➡ Don’t bother with caching until you have to.
➡ When you do need to cache (due to performance issues), cache only what is necessary.
When building a prototype or MVP, you probably shouldn’t think about caching unless there’s a specific reason to.
For instance, when I built my HyveMynds MVP, I incorporated caching because I needed to access AI embeddings frequently. These embeddings represent a large amount of data, which would have caused significant overhead if read from disk each time.
But generally when you are first starting out and finding product market fit, adding caching is more likely to increase effort and costs needlessly on features you don’t even know will matter.